― 録音音声がスローになる問題の正体と解決 ―
🧩 起きていた問題:録音音声が「スロー再生」される
iOSで開発中の音声文字起こしアプリにて、録音後の文字起こし結果が明らかに間延びしているという問題が発生。音声ファイルを再生すると、**再生スピードが異常に遅い(約0.6〜0.7倍速)**と判明。
🔍 原因究明:AudioConverterとサンプルレートの罠
原因は、マイクの実際の入力サンプルレートが 48000Hzにも関わらず、AVAudioConverter で 16000Hz に無理やり変換していたこと。
swiftコピーする編集するtry session.setPreferredSampleRate(16000)
print("🎤 実際の入力サンプルレート: \(session.sampleRate)") // → 実際は48000.0
つまり、3秒の音声が約9秒に間延びして記録されるという事態に。
✅ 解決策:変換後のバッファサイズを正確に扱う
修正ポイントは次の2つ:
1. バッファ容量を変換比に応じて計算せず、固定で確保
swiftコピーする編集するlet outputBuffer = AVAudioPCMBuffer(pcmFormat: converter.outputFormat, frameCapacity: 2048)
2. frameLengthを使ってサンプル抽出
swiftコピーする編集するlet samples = Array(
UnsafeBufferPointer(start: outputBuffer.floatChannelData![0], count: Int(outputBuffer.frameLength))
)
✍️ 教訓と今後の注意点
✔️ サンプルレートは「希望」ではない
swiftコピーする編集するtry session.setPreferredSampleRate(16000)
上記は希望にすぎず、実際のサンプルレートは session.sampleRate で確認する必要がある。
✔️ 変換バッファは常に frameLength を基準に処理すべし
swiftコピーする編集するoutputBuffer.frameLength
これを無視して長さ計算を誤ると、音声データがスロー/速すぎになる。
✔️ 音声チャンク処理は「秒数」ではなく「サンプル数」で制御
swiftコピーする編集するlet targetSampleCount = Int(sampleRate * 5) // 5秒チャンク
これがマイク入力の実サンプルレートとずれていれば、チャンクがズレる。
🎉 結果
録音音声のスピードが正常化し、文字起こしの精度も大幅に向上!
リアルタイム文字起こしとして、音声品質・変換精度ともに安定した動作が得られました。
🔚 まとめ
- 「音の歪み」は設定ミスの蓄積から生まれる
- ログ出力で 実際の環境値を必ず確認
- WhisperKit を正しく活かすには 音声信号処理の基本が不可欠
🔗 次回予告
次回は:
- 無音検出によるチャンク最適化
- 録音ファイルの MP3 変換
- バックグラウンド録音対応
などを深掘り予定です。ご期待ください!
追記 2025.10.1
iPhoneでのWhisperKitはリアルタイムは small モデルでは無理がありそう。
バッチでもMediumか、、、ってLarge V3 Turboがいいなぁ。。。とりあえず、iPhone12じゃ微妙。iPhone 16,17 だとけっこう大き目のモデルで、
リアルタイム or バッチがきっちり動くのではないかと期待はしているけれども。
実はそんなことがあり、
OpenAI whisper APIを利用したアプリを作ってみました。
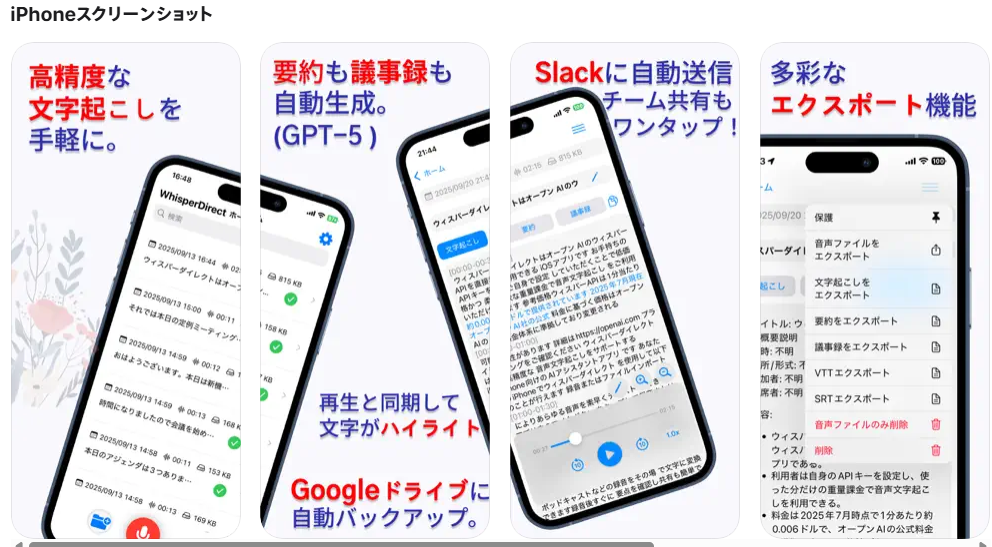
600円の買い切り。
現在の機能をずっと利用可能。
利用料はOpenAIに直接支払い、
追加料金なしの低価格従量課金。高精度文字起こし、録音/取込の即時テキスト化、
再生同期ハイライト、要約・議事録、Slack連携、字幕出力。ビジネス/学習に最適。
設定で推定コスト確認可。
Google Driveバックアップ対応。
タイムラインマーカー見返しも便利。
WhisperDirectは、ご自身のAPIキーで使える高精度の音声文字起こし&要約アプリです。
必要なときに必要な分だけOpenAI APIを使う設計なので、サブスク不要で運用できます。
価格と体験
・5回の無料体験があります
・その後は買い切りで、現在の機能を無制限で利用できます
・APIの利用料金はOpenAIに準拠(アプリ側ではAPI利用料を課金しません)
費用の目安
・Whisper API は約 $0.006/分(1時間 ≈ $0.36)
・¥500 で約9.3時間の文字起こしが可能です。
(概算 1ドル=¥150の換算、2025年9月時点のOpenAI料金を参考)
・実際の費用は音声の長さや設定により変動します
・OpenAI APIの料金は https://openai.com/ja-JP/api/pricing をご参照ください
要約・議事録用モデル
・要約/議事録機能で使用するLLMモデルは、
GPT-5 nano / GPT-5 mini / GPT-4.1 nano / GPT-4.1 mini
から選択可能(提供状況により更新される場合があります)
・数千文字規模の日本語テキストでも数円程度の低コストで処理可能です
(入力トークン、出力トークンにより変動)
主な機能
・マイクボタンで録音し、そのままテキスト化
・音声ファイルのインポート→テキスト化(共有シート対応)
・動画ファイルの取り込みに対応(音声のみ抽出・圧縮)
・再生位置に合わせて文字起こしを自動ハイライト
・任意間隔のタイムライン挿入(設定で5秒刻みに変更可)
・文字起こし内容から要約を作成
・文字起こし内容から議事録を作成(要約・議事録のプロンプトは設定で編集可)
・エクスポート:音声/テキスト/要約/議事録/字幕(VTT / SRT)
・文字起こし・要約・議事録をSlackに自動投稿
・推定コストの表示(音声長・文字数に基づく目安)
・設定画面での細かなカスタマイズ(LLMモデル選択、タイムライン間隔、プロンプトなど)
対応形式
音声: mp3, m4a, aac, wav, flac, ogg, opus, wma, amr, mpga, webm, aiff, caf
動画: mp4, mov, m4v, webm, mkv, avi, mpeg, mpg
注記
・利用にはOpenAI等のAPIキーが必要です
・価格や仕様、利用可能なモデルはOpenAIの提供状況により変更される場合があります今後はこれをベースに開発を進めて行きます~
HP
https://whisperdirect.oci.mydns.jp/
App Store
https://apps.apple.com/jp/app/whisper-direct/id6748595475